

Tuning LLMs: a galaxy of endless possibilities
Shedding light on new techniques


Since LLMs have been around, the number of new techniques in the world of AI have been growing almost as quickly as the number of new galaxies made visible by the James Webb Telescope. It is easy to lose the thread, miss the newest methods and get confused in a universe of new names.
The purpose of this article is to shed light on some new techniques whose names are not very different from some already known methods.
The outline will be:
Adaptive Tuning and Fine Tuning;
Defining Instruction Tuning and Prompt Tuning;
🚀 Job & Research opportunities, talks, and events in AI.
Let’s start!
Delving into Instruction Tuning
Instruction Tuning is not Fine Tuning! It is the next step forward. Before diving into it, let us recap some basics.
Adaptive Tuning and Fine Tuning
Starting from a pre-trained Large Language Model, we use to say that we proceed with a fine tuning when we want to train it on a specific task (and therefore data) in a supervised setting. For instance, we might fine tune a generic language model in distinguishing irony and sarcastic sentences.
Sometimes, before fine tuning on task-specific data, the model might undergo an additional pre-training phase on a large corpus of domain-specific text, helping it to adapt to the vocabulary and style of the target domain (this is named Domain Adaptive Tuning). In the previous example, we could adaptive tune our model on a huge collection of comic books.
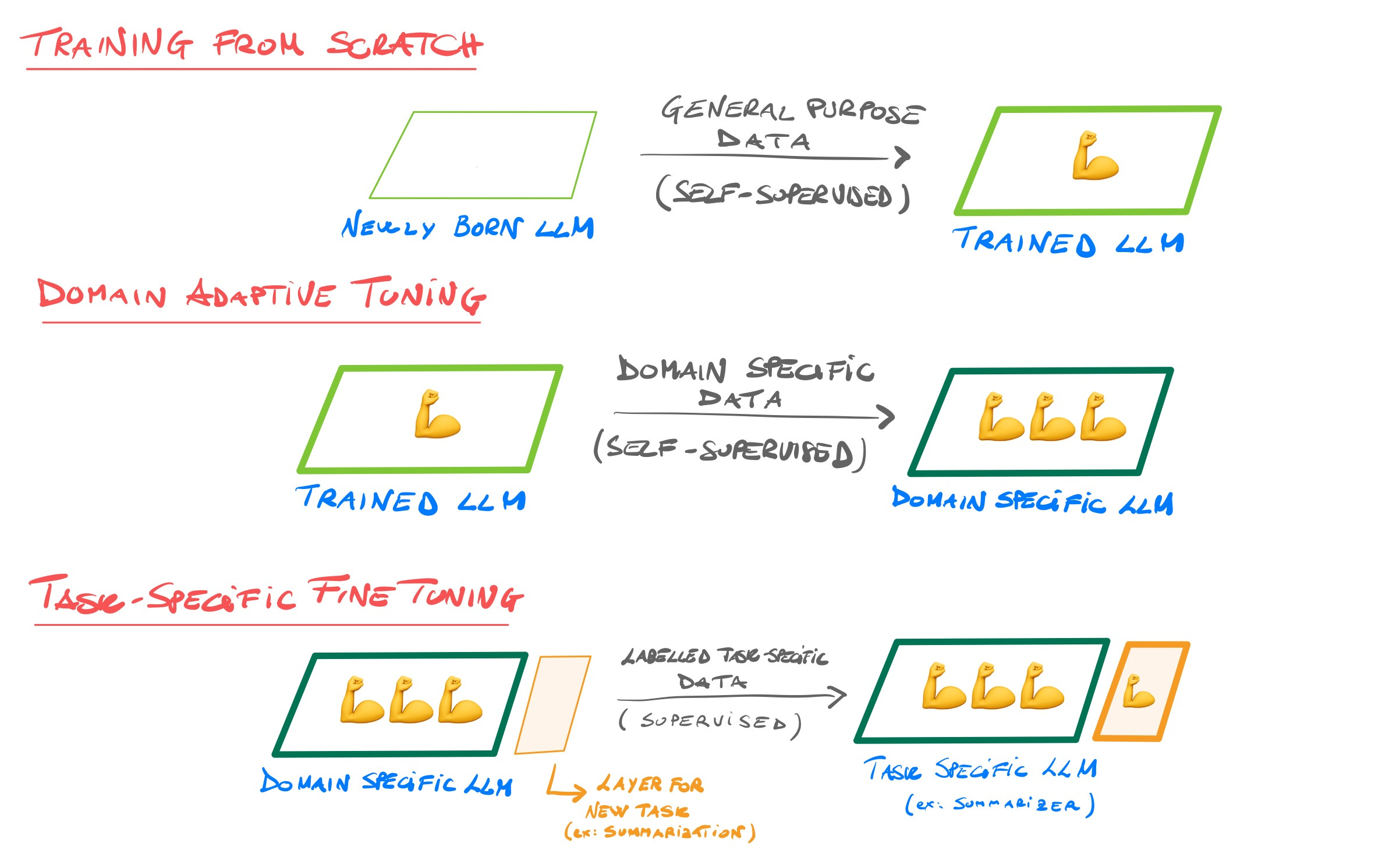
To recap, the standard procedure is
Training a model from scratch (aka pre-training) on a general purpose dataset, following a self-supervised training, such as Masked or Causal Language Modelling (MLM or CLM);
Adaptive tuning a model on a large corpus of domain-specific text, according again to MLM, CLM or similars;
Fine tuning the model on a small task-specific dataset in a supervised setting.
Instruction Tuning
Given a LLM, the problem we want to solve is:
How to turn a vanilla next-word predictor to a model that generates a good answer given a prompt?
Mathematically speaking, starting from a model trained on basics language objective P(word | context) how can we transform it into a model that, given a task/prompt, optimizes P(answer|prompt)?
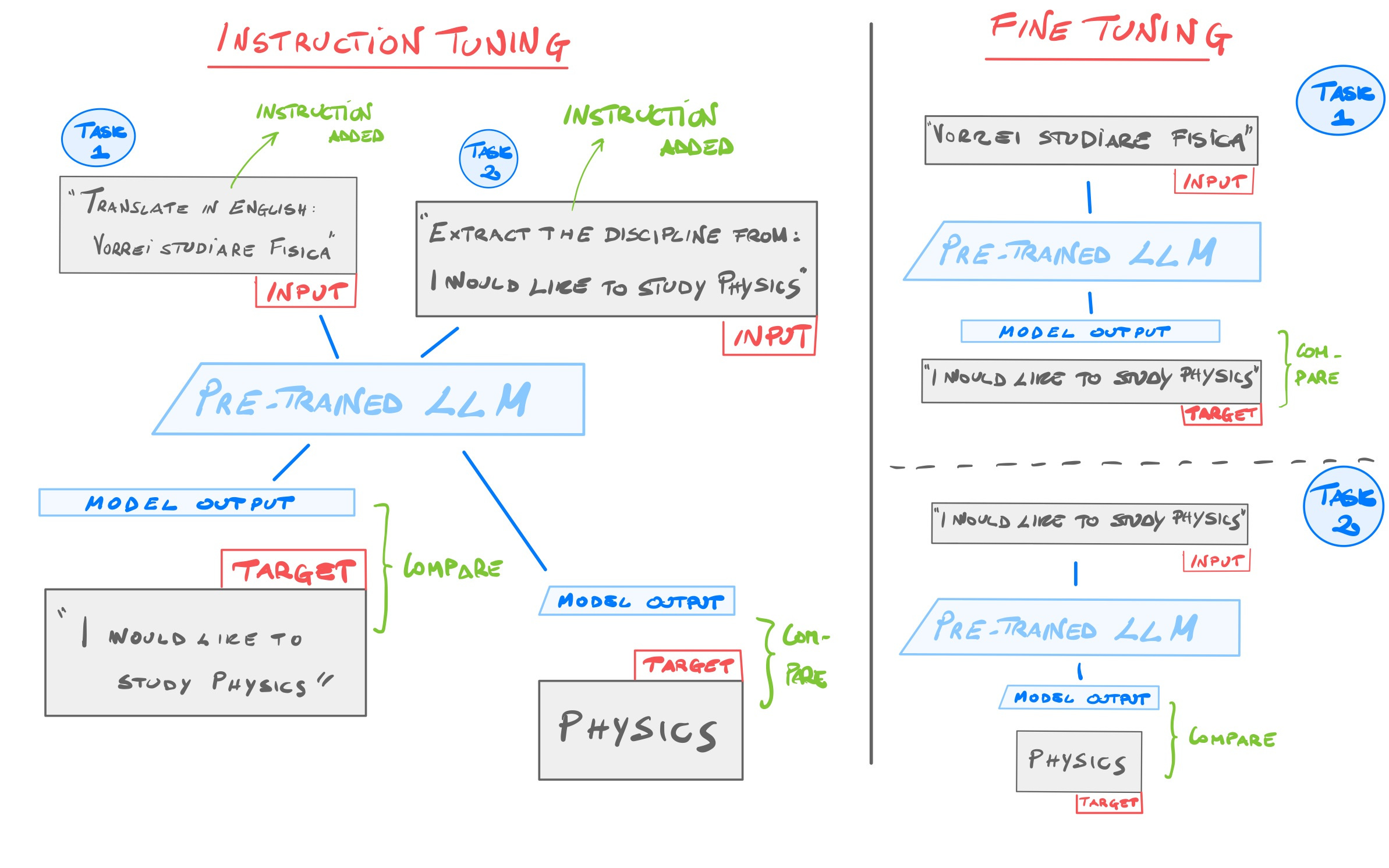
This is where Instruction Tuning comes in. It is about bridging the gap between next-word prediction objective and the user's wish for the model to follow specific instructions. This is possible by standard fine tuning an LLM using pairs of instructions and their corresponding outputs. Each data sample may have a different instruction/task with respect to the next sample.
Instruction Tuning vs Fine Tuning
There are several other methods for adapting LLMs to new tasks, such as zero-shot prompting, few-shot prompting and supervised (standard) fine tuning. Zero-shot and few-shot prompting are a simple, fast and inexpensive way to adapt the LLM to a new task. Supervised fine tuning of an LLM to a specific task is accurate, but time-consuming and expensive.
While standard fine tuning focuses on a specific task (e.g. NER), instruction tuning can train the model simultaneously on many tasks, as mentioned before.
If you wish to better grasp instruction tuning, you can find more on this blog by
. To do some practice, I found this notebook where LLaMa 2 is instruction tuned by Philipp Schmid. If you are looking instead for a collection of open-source instruction tuning datasets, checkout this github repository (text and multimodal sets).Delving into Prompt Tuning
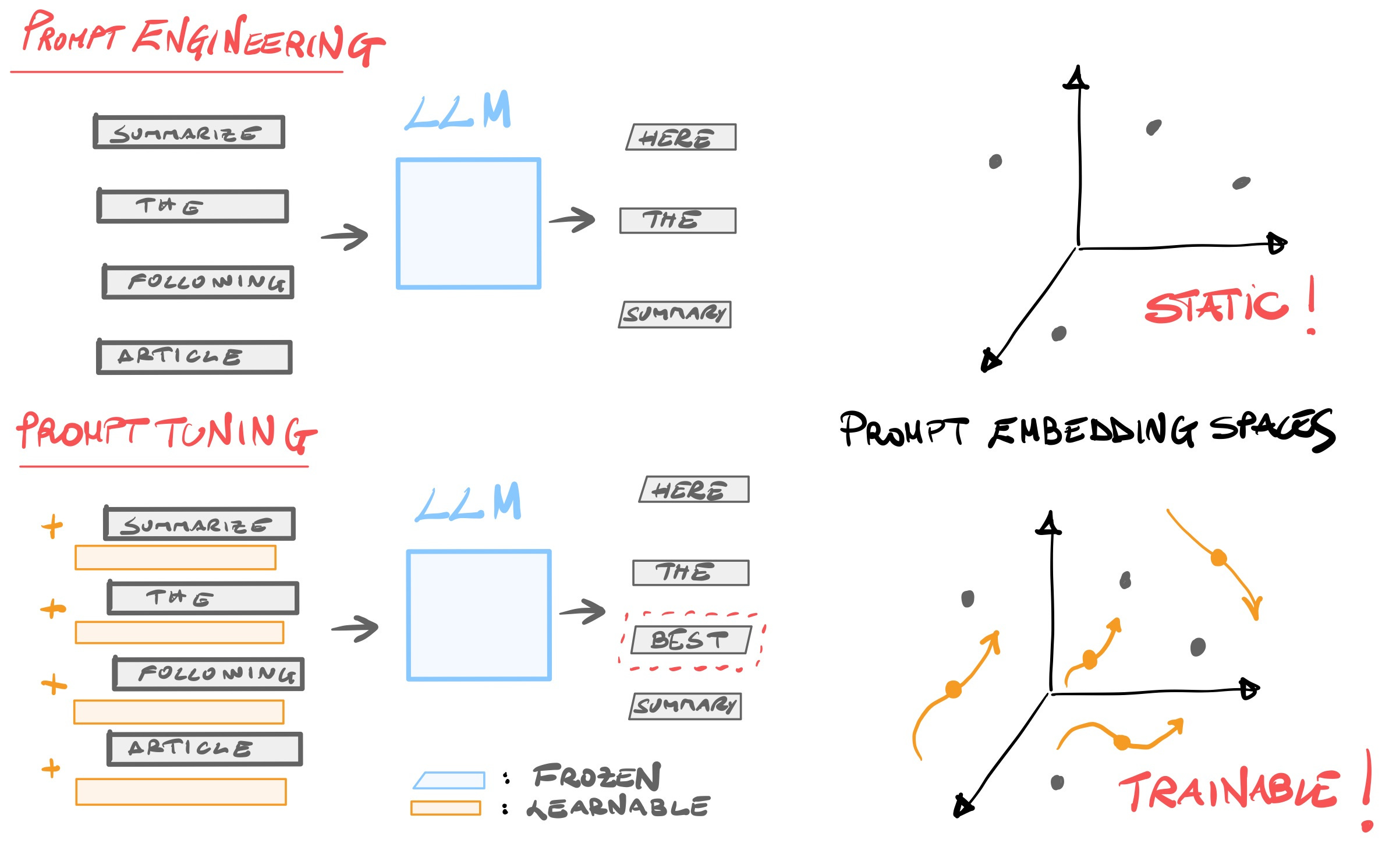
Prompt Engineering is the widely known art of designing by hand hard prompts, i.e. optimal static prompts that serve to instantiate an LLM and direct its behaviour towards the desired results without further training the model (i.e. without updating its weights). It is sometimes referred to as a in-context prompting.
Despite the enormous success of Prompt Engineering, it has several limitations. Crafting the perfect prompt demands a lot of trial and error. In addition, it is limited by the context window.
Introducing Prompt Tuning
This is where Prompt Tuning comes in, introducing soft prompts (original paper). These are additional trainable tokens that are added to the hard prompt. By supervised training these additional parameters for a given downstream task, we tailor the model's response more precisely. The advantage of Prompt Tuning over standard fine-tuning is that only a few new embedding weights are trained, instead of the entire pre-trained LLM (see the picture!). For the above reasons, soft prompts are usually referred as AI-designed prompts.
The intention of this article was not to list all the possible ways of fine-tuning an LLM but to highlight some of them by showing the differences. Going back to the opening words, there is a galaxy of different techniques and certainly a universe of many more yet to be discovered.
Opportunities, talks, and events
I share some opportunities from my network that you might find interesting:
🚀 Job opportunities:
An intern position is opened at Moody's Quantum Group;
Metis, an early-stage AI startup active in NLP for document processing automation, is looking for a Full-stack Software Engineer;
Briink, an AI-powered Green Tech startup, opened an AI Engineer position;
Carbon Re, an AI company focusing on cement and steel decarbonization, is looking for a Lead Machine Learning Engineer;
🔬 Research opportunities:
New positions at different levels (post-degree, post-doc and researcher positions) on research topics at the intersection of HPC and AI for Climate Change at University of Trento (more info here);
Two open positions for Computer Scientists on Multi-agents Gene Networks and Machine Learning in an ERC project in Computational Biology at Bocconi University (more info here);
📚 Learning opportunities:
Application are now open for 10 grants (8-week hands-on AI programme on real-world challenge) at the Pi School of AI Pi School starting around April (apply here);
Application are now open for several full fellowships at the Master in High-performance Computing (MHPC, SISSA/ICTP, Trieste), a 15-months-program for future experts in HPC, AI and Quantum Computing (Link to apply);
Dati, Innovazione e Sostenibilità at EIIS - European Institute of Innovation for Sustainability (in Italiano): un evento per introdurre ad alto livello l'AI e imparare a creare tramite questa strategie di sostenibilità.
A Tech Talk given by Nicola Procopio at Pi School about the open-source project Cheshire Cat AI: A Production Ready AI Assistant Framework.
You can find me on LinkedIn or Twitter, where I share Science & Tech news. If you wish to book a call or view my lectures and courses (technical and non-technical), you can find me here.